“日本最强AI”光速塌房,都怪中国DeepSeek太强?
2026-03-19 16:35

作者|Hayward
原创首发|蓝字计划
连日本人自己都绷不住了。
3 月 17 日,日本科技公司乐天高调发布了新一代 AI 大模型 Rakuten AI 3.0,宣称是日本最大、性能最强的 AI 大模型。
这款模型来头不小:一方面,它背后有日本经济产业省支持的 GENIAC 项目站台,算是“国家队”级别的大模型;另一方面,它还拥有一个相当唬人的标签,7000 亿参数。
这什么概念?
哪怕按更具体的口径来看,它的总参数规模也有 671B,依然属于当前开源模型里的第一梯队,和 DeepSeek V3 坐一桌。
背靠日本国内最大靠山,参数又非常突出,对于这款模型的发布,乐天底气十足,连“(日本)国产模型的逆袭”都喊出来了。

但是,日本网友还没来得及为Rakuten AI 3.0 开香槟,一场来自开源社区的技术打假就给他们浇了一盆冷水。
这款号称“日本最强、性能最强”的大模型,竟然是咱们中国开源大模型,DeepSeek-V3 的日语“套壳版”。

日本的荣光,却出身不良
和绝大多数的打假“后知后觉”不同,Rakuten AI 3.0 的吹牛行为甚至挺不过一个下午。
就在模型出来的几个小时里,开源社区的大神们就发现,这款加上了非常多牛逼限定词的 AI 大模型,有猫腻。
甚至乐天都没有过多的“掩饰”,因为Rakuten AI 3.0赫然在Hugging Face上的config.json文件里写着:
model_type: deepseek_v3
architectures: DeepseekV3ForCausalLM
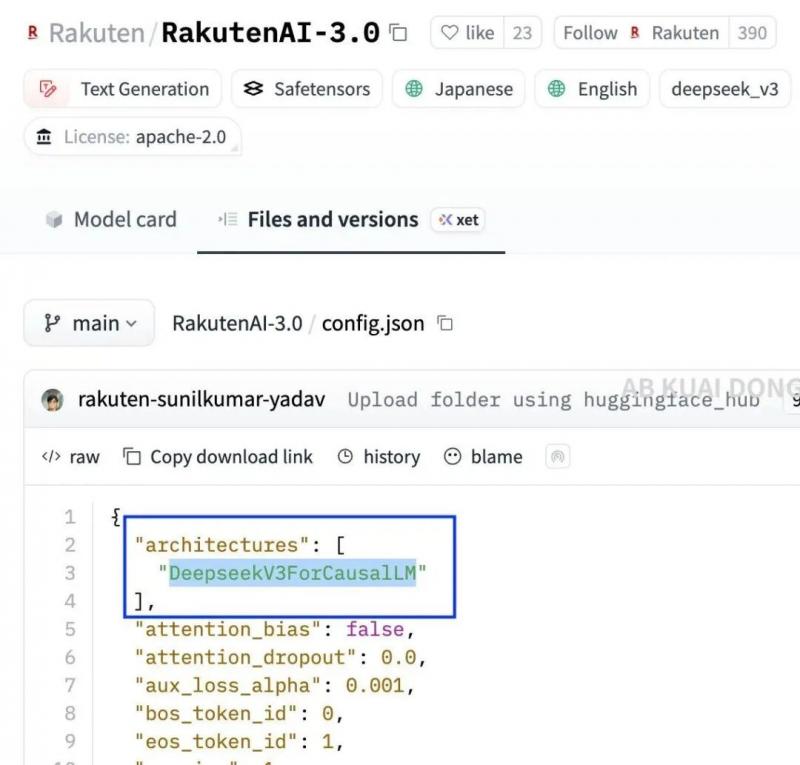
这就相当于明牌告诉大家,这款模型的底层架构来自 DeepSeek V3。
当然,DeepSeek V3 作为一款开源模型,被学习、借鉴、使用来作为模型架构也正常不过,毕竟这就是开源的初心;
但Rakuten AI 3.0 的问题在于,在发布的时候它丝毫没有提及使用了DeepSeek V3 的架构,还搬出了“自主研发”“日本最强”“日本最大”等限定词,看上去真的是由乐天从 0 到 1,自主鼓捣出来的大模型。

这也是开源社区最不满的地方:这款模型在上传的时候,没有充分保留 DeepSeek 原有的归属/许可证声明;直到被社区抓包之后,才悄悄地补上了 NOTICE 文件。
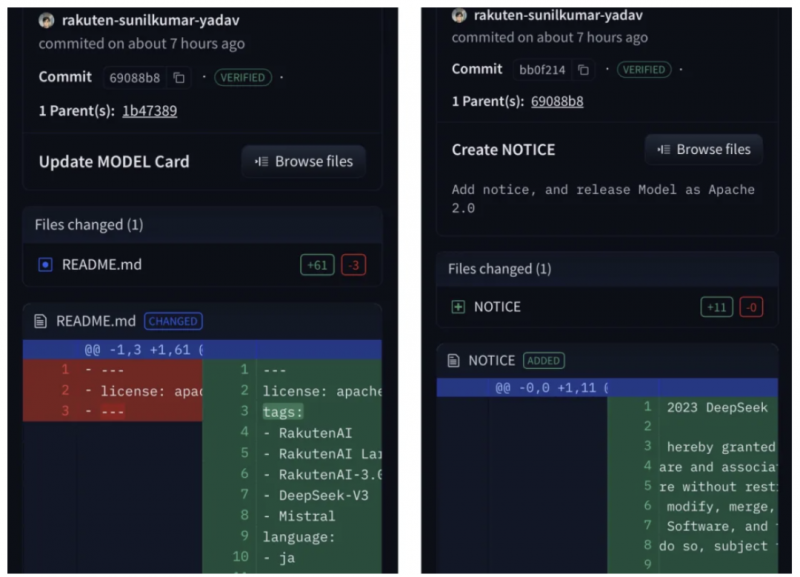
乐天的这种做法,显然是违背了开源精神,“需要保留原许可证和归属”的要求。
在使出这一招“亡羊补牢”之后,别说路人,连日本网友都好感都败光了。对于这款模型,日本网友都评论基本都是:
“GENIAC项目花纳税人的钱,就做个DeepSeek的日语fine-tune版?”
“自称日本最大高性能,却是中国的日语版。”

那么这款模型的性能怎么样呢?
根据乐天官方陆续公布的数据,Rakuten AI 3.0 的纸面成绩其实相当能打。
像 Japanese MT-Bench 这样的日语综合基准,它已经跑赢了 GPT-4o;而在日本文化理解、敬语表达、商务邮件、报告写作、文档分析这些更偏本土语境的任务里,表现也明显很强。
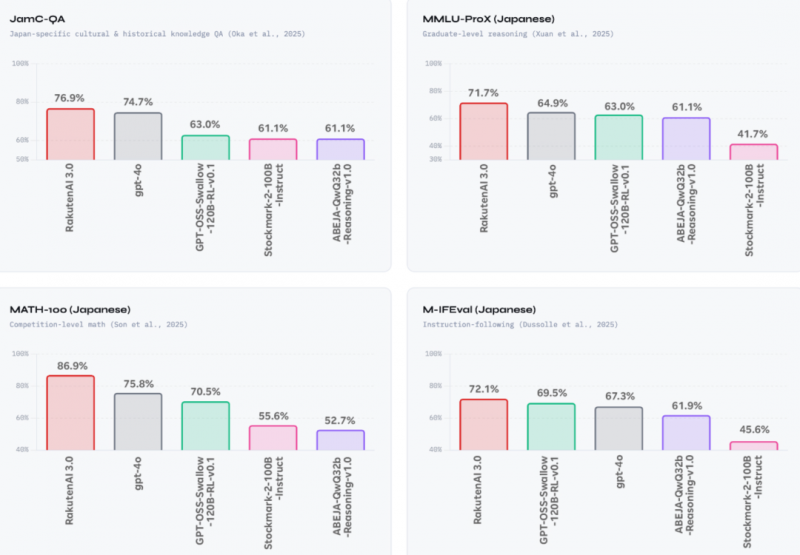
再加上它虽然总参数接近 7000 亿,但因为用了 MoE 稀疏架构,单次推理实际激活的参数并不高,成本还能被压到相当前沿闭源模型的10%左右。
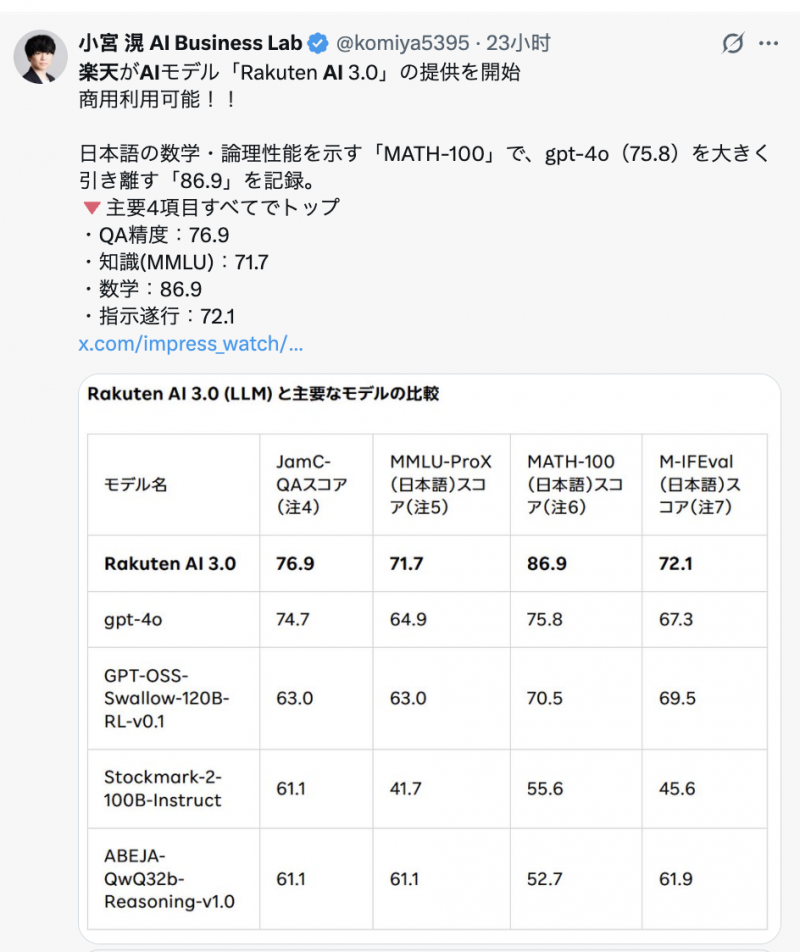
也就是说,这模型不只是“成绩好看”,而且用起来还非常省钱。
但熟悉大模型的人一眼就看出了:这些不都是 DeepSeek 本来的优势吗?
是的,毕竟是一款基于 DeepSeek-V3 架构、再做日语数据微调和本土化优化的大模型,Rakuten AI 3.0 的表现越是厉害,就越是能证明 DeepSeek 厉害,这也是 X 上相当一部分日本网友破防的点:
“日本政府用了纳税人的钱来支持你们,你们却用来证明中国的 DeepSeek 牛逼?”
估计梁文锋看到这出戏,做梦都得笑醒。
司空见惯的“抄袭”
但是,日本的网友们可能也有点“失忆症”了,毕竟从日本 AI 大模型的发展历程来看,抄袭,或者优雅点说:“套壳”,不是常态吗?
Rakuten AI 3.0 可不是第一个使用了别家大模型架构作为基座的日本模型。
一个典型例子,是日本 AI 公司ABEJA 在 2025 年 4 月左右推出的小型日语专精推理模型:ABEJA QwQ 32b。

光看这个名字,其实就已经名牌了。
毕竟连 QwQ 这个阿里千问系最标志性的前缀,它都懒得改。
而实际情况也差不多。
这款模型的底座,本来就是 Qwen2.5 + QwQ-32B,ABEJA 做的事情,说白了就是先拿千问模型做日语持续预训练,再把推理能力整合进去,最后补一轮日语强化和微调。
本质上,它和乐天这次的路数并没有什么不同:都是拿中国开源大模型当基座,再靠本土数据和场景去做一层“日本化”包装。
只不过,ABEJA 至少没有把自己演成什么从 0 到 1 横空出世的“日本最强原创模型”。
它不但把底座和训练路径写清楚,连阿里那边都没有介意,阿里巴巴官方 X 账号甚至还专门转发庆祝,大意就是:ABEJA 做的日语推理模型,成绩已经超过了 GPT-4o。
同样是“套壳”,ABEJA 当然也谈不上多原创,只不过人家至少没有一边踩着别人的底座,一边还忙着擦脚印。
除了ABEJA 和乐天,不少日本公司其实也大体走的是这条路。
像 Lightblue、ELYZA 这些做日语模型的玩家,底下是 Qwen、Llama 等现成底座,有的也会结合 DeepSeek、Mistral 这类强模型能力做本土化,上面再糊一层更懂日本企业文档、客服语料、敬语语境、制造业日志的数据,把它调成一个“更会说日本话、更会干日本活”的版本。
日经新闻网之前曾报道过,“「AIモデルスコア」で 日本企業が開発した上位10モデルのうち、新興ABEJA(アベジャ)のモデルなど計6種がディープシークや Qwen を基盤に開発されていた。”
翻译过来,就是现在日本公司推出的前10大模型里,有 6 个都是基于 DeepSeek 或Qwen 进行二次开发。
其实,这在 AI 圈本来也不算是什么原则性问题,全球 AI 行业现在本来就是这么玩的。
美国也好,欧洲也好,中国也好,别说二三线团队了,很多一线团队其实也在走这条路:拿Qwen 做推理增强,拿 DeepSeek 做蒸馏和本地部署,拿 Llama 做行业版,拿 Mistral 做轻量化和边缘场景。
毕竟,从头训练一个前沿基座,烧掉的是天文数字级别的算力、资金和人才;但如果你已经有了一个足够强的开源底座,真正决定你能不能跑出来的,反而是后面的数据、场景和落地能力。
所以,乐天这次的“炎上”,本质不是因为“抄袭”而触犯天条,而是干得太不体面了。
一边吃着开源模型的红利,一边又拼命把自己往“自主研发”“日本最强”“日本最大”上靠;一边站在 DeepSeek 的肩膀上,一边又不愿把这件事说透,甚至连许可证和归属都都悄悄藏起来。
别人套壳,至少套得坦坦荡荡;乐天套壳,却偏偏还想演成“全靠自己”。
又或许,乐天这次“不体面”的背后,折射出的,只是整个日本科技领域已经落后于世界的冰山一角。
日本 IT业,失落的 30 年
1990 年,随着经济泡沫被刺破,整个日本都仿佛被按下了暂停键。
股价暴跌、地价跳水、不良债权爆发、银行惜贷、企业连锁倒闭……整个日本经济像多米诺骨牌一样接连崩塌,正式跌入“平成不况”,并由此开启了失落的 10 年、20 年,乃至 30 年。
而在这样的背景下,日本 IT 行业的轨迹,也几乎成了这场长期停滞的缩影。
关于日本的“笑话”大家已经看到非常多了:
都 2024 年了,日本政府居然还在和软盘“决战到天明”。

直到去年 6 月,日本数字厅才终于废掉了 1034 条还要求用软盘等介质提交材料的规定,只剩下一条和汽车回收有关的规定没处理完。
在 AI、大模型、云计算都已经卷到天上的年代,日本政府居然还在认真讨论“软盘要不要退役”这种问题。
传真机也差不多。
这些年外界老拿“日本还在用传真”开涮,听上去像段子,结果很多时候还真不是段子。
日本文部科学省自己给出的“教育DX”(DX,Digital Transformation,数字转型)目标里,甚至把“原则上废止学校之间通过传真机往来和盖章”单独列成了 KPI;而且这个目标之所以要专门写出来,恰恰是因为现实里它远远没有完成。
说白了,如果一个国家的教育系统到了 2024 年还要把“别再传真、别再盖章”写成数字化改革目标,那它的问题显然不是某个软件没装好那么简单了。
更尴尬的是,日本自己其实也不是没意识到问题。
无论是成立数字厅,还是高调对软盘、传真“宣战”,都说明日本政府很清楚自己在数字化这件事上慢了半拍。
可问题在于,知道归知道,改起来却总像在沼泽地里跑步:
一边是官僚系统的惯性,一边是纸质文件、印章文化、老旧流程的路径依赖,再叠上高龄化和 IT 人才短缺,最后就变成了一个很别扭的局面:
大家都知道该变,但谁都没办法一下子把旧时代连根拔掉。
就连日本自己的政策讨论里,也长期把数字人才不足当成结构性问题来看;经产省更早前的测算里,到 2030 年日本 IT 人才缺口最高可接近 45 万人。
但程序员不够,怎么办?
从官方和产业界的表态来看,他们显然也在把生成式 AI 当成另一条捷径:既然程序员不够,那就尽量让更多懂业务的人,直接通过自然语言下指令,把需求更快变成代码、文档和系统。
所以,Rakuten AI 3.0 这件事,理应是整个 2026,日本 AI 圈的一个里程碑式事件。
因为它更像是日本 IT 困境的一次浓缩展示:政府给资源,企业拿补贴,嘴上喊着“日本最强”“本土自研”,结果掀开盖子一看,底下还是 DeepSeek V3。

这当然不说明日本公司不会做 AI,也不说明日本没有技术实力。
但却反映了,那个曾经靠电子消费品、半导体、工业产品征服世界的日本,在今天这场由软件、数据、云和大模型主导的新技术竞赛里,已经很难再靠自己完整定义游戏规则了。
连最想证明“日本也有自己的旗舰大模型”的关键时刻,最后都得站在中国开源模型的肩膀上,这才是整件事最扎心的地方。
金角财经声明:文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担!

